
ManufacturingUSA:
B2B Lead Qualification Chatbot
Conversational lead qualification chatbot with BANT-framework questions, real-time scoring, and HubSpot integration for automatic routing.
N8NReact jsPythonSalesforce
AI document processing turns unstructured files like contracts, invoices, and reports into structured, searchable data. Bitontree builds production-grade intelligent document processing systems and RAG pipelines that extract, classify, and summarize documents at scale, so your team stops doing manual data entry.
We engineer six categories of AI document processing systems. Each is a production-grade system type built around a core capability: contract analysis, document Q&A, knowledge retrieval, due diligence, financial extraction, or classification.

We build AI systems that read contracts, extract indemnity, liability, termination, and payment clauses, and compare language against your approved templates. The system assigns risk scores, generates redline suggestions with explanations, tracks obligations and renewal dates, and processes hundreds of contracts in parallel with structured output for review teams.

We build RAG systems that connect a large language model directly to your document sets. Users ask plain-language questions, the system retrieves relevant passages, generates an accurate answer, and cites its sources with page numbers. It searches across document types, formats, and repositories in a single query, with conversation memory and access control.

We build knowledge base AI chatbots that index your company knowledge from Confluence, Notion, Google Drive, SharePoint, and Slack, then make it accessible through conversation. The system uses semantic search, indexes new documents in real time, adjusts responses by user role, and routes low-confidence questions to the right person.

We build AI document processing systems that review M&A data rooms at machine speed. The system ingests entire virtual data rooms, flags litigation exposure, regulatory violations, and contract risks, extracts parties, dates, and obligations into structured databases, identifies contradictions between documents, and generates executive summaries with risk ratings.

We build AI document extraction systems that turn invoices, tax forms, financial statements, and receipts into clean, structured data ready for your ERP or accounting platform. The system handles 40+ formats, parses tax documents, normalizes financial statements across periods, and validates extracted data against existing records.

We build classification systems that auto-categorize inbound documents by type, route each to the right team or workflow, extract metadata on arrival, and score priority so urgent documents get escalated. The system learns your organization's specific document categories and classification rules through custom taxonomies.
Beyond system categories, here are the specific document workflows we automate, mapped to the industries that run them and the proof behind each. These are the six highest-ROI AI data extraction and automation use cases we deliver.
Extracts header, line items, tax, and totals from PDF or scanned invoices. Validates against purchase orders, posts to the accounting system, and flags exceptions for human review. Replaces three-way matching done by hand.
Reads contracts, extracts key clauses (term, renewal, indemnity, jurisdiction), and flags non-standard language against your playbook. Outputs a structured summary and a redline list for the legal reviewer.
Reads insurance claims, medical records, or warranty submissions, extracts the structured fields, runs the policy and rules check, and routes for approval or denial. Removes the manual transcription step that creates most claim-cycle delay.
AI document processing and intelligent search apply wherever organizations deal with high document volumes, regulatory requirements, or distributed knowledge. Here are the six industries where document AI delivers the strongest ROI.
The primary industry for document AI. Contracts, case files, regulatory filings, discovery documents, and compliance records are all unstructured and all critical. We build contract analysis and redlining at scale, legal research acceleration through RAG-powered Q&A, due diligence automation for M&A transactions, and compliance document tracking and classification.
Invoices, tax filings, audit documents, and financial statements. High volume, zero tolerance for errors. We build automated invoice processing and reconciliation, tax document extraction and compliance mapping, audit document preparation, and financial statement analysis and normalization.
Bills of lading, customs declarations, shipping manifests, and procurement documents cross borders and formats. We build shipping document extraction and validation, customs paperwork automation, supplier contract management, and purchase order processing and matching.
RAG, Retrieval-Augmented Generation, is the core technical approach behind most document AI systems. A RAG pipeline retrieves relevant passages from your documents and feeds them to a large language model, so every answer is grounded in your data. Here is how a production RAG pipeline works, step by step.
Raw documents enter the pipeline: PDFs, Word docs, Excel files, emails, scanned images, web pages. The ingestion layer normalizes formats and extracts text. For scanned documents and images, OCR converts visual content to machine-readable text. We use Tesseract for open-source OCR workloads and Azure Document Intelligence for high-accuracy enterprise extraction.
Format normalization
Text extraction
OCR processing
Multi-source intake
We build AI document processing systems on a proven, production-grade technology stack. These are the tools our engineers use across orchestration, language models, vector search, document parsing, monitoring, and deployment, selected per project based on your accuracy, cost, and compliance requirements.
LangChain
LlamaIndex
Haystack
DSPy
LangGraph
Semantic Kernel
CrewAI
A common question in document AI projects: should you fine-tune an LLM on your data or build a RAG pipeline? The table below compares both approaches across the factors that matter most for document AI.
| Factor | RAG | Fine-Tuning |
|---|---|---|
| Data changes frequently | Best choice, no retraining needed | Requires full retraining |
| Source attribution | Built in, every answer cited | Not native to the model |
| Data privacy | Content stays out of model training | Content used during training |
Real AI document processing systems we have shipped to production. Each project started with a manual, document-heavy workflow and ended with measurable gains in accuracy, speed, and cost.
Conversational lead qualification chatbot with BANT-framework questions, real-time scoring, and HubSpot integration for automatic routing.
Every project is different. These ranges reflect typical AI document processing engagements based on scope and complexity.
6-10 WEEKS
$30K - $60K
Includes document ingestion pipeline, embedding and vector storage, RAG-powered Q&A interface, access controls, deployment, and initial training. Covers up to 3 data sources and standard integrations.
12-20 WEEKS
$80K - $200K+
Includes custom document processing pipelines, multi-format extraction, classification systems, RAG infrastructure, enterprise integrations, security and compliance configurations, and ongoing optimization.
Document complexity: standardized forms cost less than freeform contracts or handwritten notes
Volume: processing 1,000 documents per month differs from 1,000,000
Accuracy requirements: 95% is achievable quickly, 99.5% requires more training data and validation
Integration depth: standalone systems cost less than ERP, CRM, and compliance platform integrations
Security and compliance: HIPAA, SOC 2, data residency, and air-gapped deployments add scope
Discover what our clients say about working with us and how we’ve contributed to their success.
Logistics
Our AP team used to spend three days processing a single invoice. Now the agent does it in 20 minutes. Honestly, the biggest surprise wasn't the speed - it was how well it handles the weird edge cases we thought would always need a human.

Director of Operations
Logistics
Two people spent every morning copy-pasting tracking data into CargoWise. Now the AI does it overnight - 200+ shipments updated, clients notified, exceptions flagged before we walk in.

Head of Operations
Logistics
Bitontree built our invoice processing system in under five months, and our AP team finally has breathing room. Invoices that used to take minutes to key in are now processed in seconds, error rates dropped to near zero, and the system handles vendor formats and languages our previous tool could not touch. The ERP integration was clean from day one - no rekeying, no manual reconciliation.

Operations Director
Logistics
Our AP team used to spend three days processing a single invoice. Now the agent does it in 20 minutes. Honestly, the biggest surprise wasn't the speed - it was how well it handles the weird edge cases we thought would always need a human.
Director of Operations
Stay informed with the newest happenings in the world of emerging technologies.
Builds retrieval-powered AI systems that access, reason over, and deliver accurate insights from your data.
Designs, deploys, and manages intelligent agents that understand, decide, and act across business workflows.
Automates workflows, reduces manual effort, and streamlines operations with intelligent, decision-driven AI systems.
AI document processing, also called intelligent document processing, uses machine learning, OCR, and large language models to extract, classify, search, and summarize data from unstructured documents like contracts, invoices, and reports. It turns document chaos into structured, searchable data without manual data entry.
RAG retrieves relevant passages from your documents at query time and feeds them to an LLM. Fine-tuning trains the model on your data. RAG is better when your data changes frequently, you need source citations, or data privacy prevents model training on your content. Most enterprise document AI projects benefit from RAG.
Accuracy depends on document quality, format consistency, and the type of data being extracted. For structured documents like invoices and tax forms, we consistently achieve 95 to 99% accuracy. For unstructured documents like contracts, accuracy typically ranges from 90 to 97%. We build validation workflows that flag low-confidence extractions for human review.
Our pipelines handle PDF, Word, Excel, PowerPoint, plain text, HTML, email, images, and scanned documents. For scanned and image-based documents, we use OCR to extract text. We also support structured data formats like JSON, CSV, and XML.
Document data never leaves your approved infrastructure unless you explicitly choose a cloud-hosted solution. We deploy on your cloud environment or on-premises. All data is encrypted in transit and at rest. For regulated industries, we build pipelines that meet HIPAA, SOC 2, and GDPR requirements.
Yes. Our OCR and extraction pipelines support 50+ languages. RAG pipelines work with multilingual embedding models that understand semantic meaning across languages. A user can ask a question in English and get an answer drawn from a German contract or a Japanese invoice.
A typical knowledge base of 10,000 documents indexes in hours, not days. Scanned documents take longer due to OCR processing. After initial indexing, new documents get processed incrementally, usually within minutes of upload.
Yes. We build integrations with the tools your team already uses, including Salesforce, HubSpot, SharePoint, Google Workspace, Slack, Microsoft Teams, NetSuite, QuickBooks, and custom ERPs. API-first architecture means any system with an API can connect to your document AI pipeline.
Connect with our Experts and Elevate your business performance with our AI Development services.

0+
Years Of Experience

0+
Skilled Professionals

0+
Projects Delivered

0+
Global Clientele Served
Auto-classifies inbound documents (invoices versus POs versus receipts versus contracts) and routes each to the right system or owner. Removes the manual sorting queue that slows down ops teams handling mixed document streams.
Reads patient intake forms, loan applications, KYC submissions, or other semi-structured forms. Extracts fields, validates against rules, and posts to the system of record. Handles handwritten, scanned, and digital.
Reviews documents (contracts, communications, transaction records) against compliance rules (HIPAA, SOC 2, OFAC, GDPR). Flags violations, builds the audit log, and surfaces remediation tasks.
Patient records, insurance documents, clinical trial data, and regulatory submissions, with privacy requirements adding complexity. We build medical record extraction with HIPAA-compliant pipelines, insurance claim document processing, clinical trial document organization, and regulatory submission preparation.
Internal knowledge bases, customer documentation, product specifications, and support tickets. We build product documentation search and Q&A, customer support knowledge base chatbots, technical documentation management, and internal wiki consolidation and search.
Lease agreements, property disclosures, title documents, and inspection reports. We build lease abstraction and clause extraction, property document classification and routing, title search document analysis, and compliance document tracking.
Full documents are too large for embedding models and retrieval systems. Chunking breaks documents into smaller segments. Chunk size matters: too small and you lose context, too large and retrieval precision drops. We test fixed-size, recursive, semantic, and document-structure-aware chunking strategies per project.
Segment sizing
Strategy selection
Context preservation
Structure-aware splitting
Each chunk gets converted into a numerical vector, a mathematical representation of its meaning. We use OpenAI embeddings, Cohere embeddings, or open-source alternatives depending on cost, performance, and data privacy requirements. Embeddings capture semantic meaning, so phrases with no shared keywords still map to nearby points in vector space.
Vector conversion
Semantic encoding
Model selection
Privacy-aware processing
Embeddings get stored in a vector database optimized for similarity search. We work with Pinecone (managed, zero infrastructure overhead), Weaviate (open-source with strong hybrid search), Qdrant (high-performance, self-hosted), and pgvector (PostgreSQL extension for teams already running Postgres).
Database selection
Index configuration
Similarity search setup
Scale planning
When a user asks a question, the query gets embedded using the same model. The vector database returns the most semantically similar chunks. We add re-ranking to improve precision and hybrid retrieval that combines vector similarity with keyword search, catching both semantic and exact-term matches.
Query embedding
Similarity matching
Re-ranking
Hybrid retrieval
The retrieved chunks and the user's question go to a large language model. The LLM generates a response grounded in the retrieved content. We use prompt engineering and guardrails to keep responses factual. When the retrieved content does not contain enough information, the system says so instead of guessing.
Grounded generation
Prompt engineering
Factual guardrails
Fallback handling
Every response includes citations: document name, page number, section, and the specific passage used. Users verify answers against the original source. Trust comes from transparency.
Source citation
Page referencing
Passage linking
Answer verification
Flowise
Pinecone
Weaviate
Qdrant
pgvector
Milvus
ChromaDB
Elasticsearch
FAISS
GPT-4o
Claude
Gemini
Llama
Mistral
Cohere Command
Qwen
DeepSeek
OpenAI text-embedding-3
Cohere Embed
Voyage AI
Jina Embeddings
AWS
Azure
Google Cloud
Docker
Kubernetes
Modal
LangSmith
Hugging Face
Tesseract
Azure Document Intelligence
AWS Textract
Google Document AI
Unstructured.io
LlamaParse
PyMuPDF
Apache Tika
| Specific style, tone, or format | Limited control | Best choice |
| Narrow fixed-schema task | Works well | Often the better fit |
| Swapping LLM providers | Easy, no retraining | Requires retraining |
| Retrieval latency | Adds a retrieval step | No retrieval step |
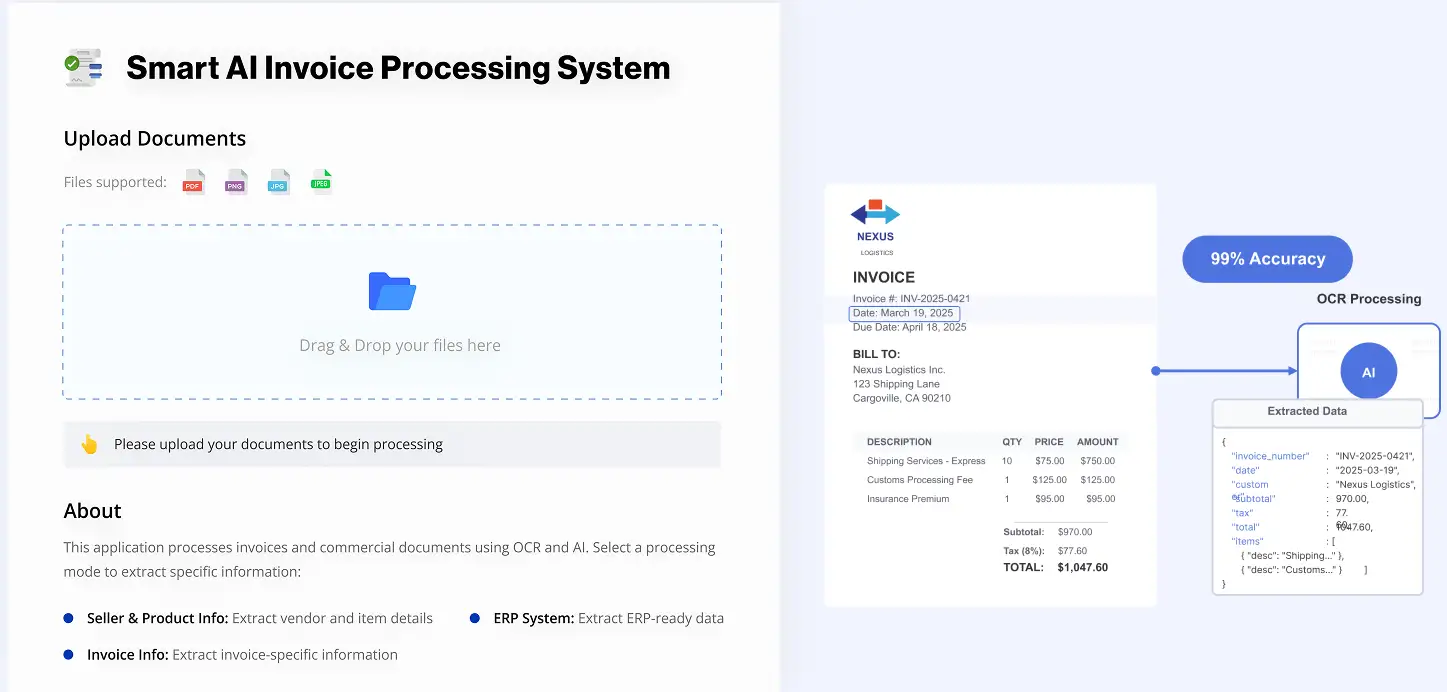
AI-powered invoice processing for a Singapore-based logistics enterprise. OCR and ML automate data extraction, validate against business rules, and process invoices end-to-end across multiple formats and currencies.


